Enhance Eye Disease Detection using Learnable Probabilistic Discrete Latents in Machine Learning Architectures
View the code here.
This paper has been submitted for review to Transactions on Machine Learning Research. You can view the preprint on arXiv.
Abstract
Ocular diseases, including diabetic retinopathy and glaucoma, present a significant public health challenge due to their high prevalence and potential for causing vision impairment. Early and accurate diagnosis is crucial for effective treatment and management. In recent years, deep learning models have emerged as powerful tools for analysing medical images, such as retina imaging. However, challenges persist in model relibability and uncertainty estimation, which are critical for clinical decision-making. This study leverages the probabilistic framework of Generative Flow Networks (GFlowNets) to learn the posterior distribution over latent discrete dropout masks for the classification and analysis of ocular diseases using fundus images. We develop a robust and generalizable method that utilizes GFlowOut integrated with ResNet18 and ViT models as the backbone in identifying various ocular conditions. This study employs a unique set of dropout masks - none, random, bottomup, and topdown - to enhance model performance in analyzing these fundus images. Our results demonstrate that our learnable probablistic latents significantly improves accuracy, outperforming the traditional dropout approach. We utilize a gradient map calculation method, Grad-CAM, to assess model explainability, observing that the model accurately focuses on critical image regions for predictions. The integration of GFlowOut in neural networks presents a promising advancement in the automated diagnosis of ocular diseases, with implications for improving clinical workflows and patient outcomes.
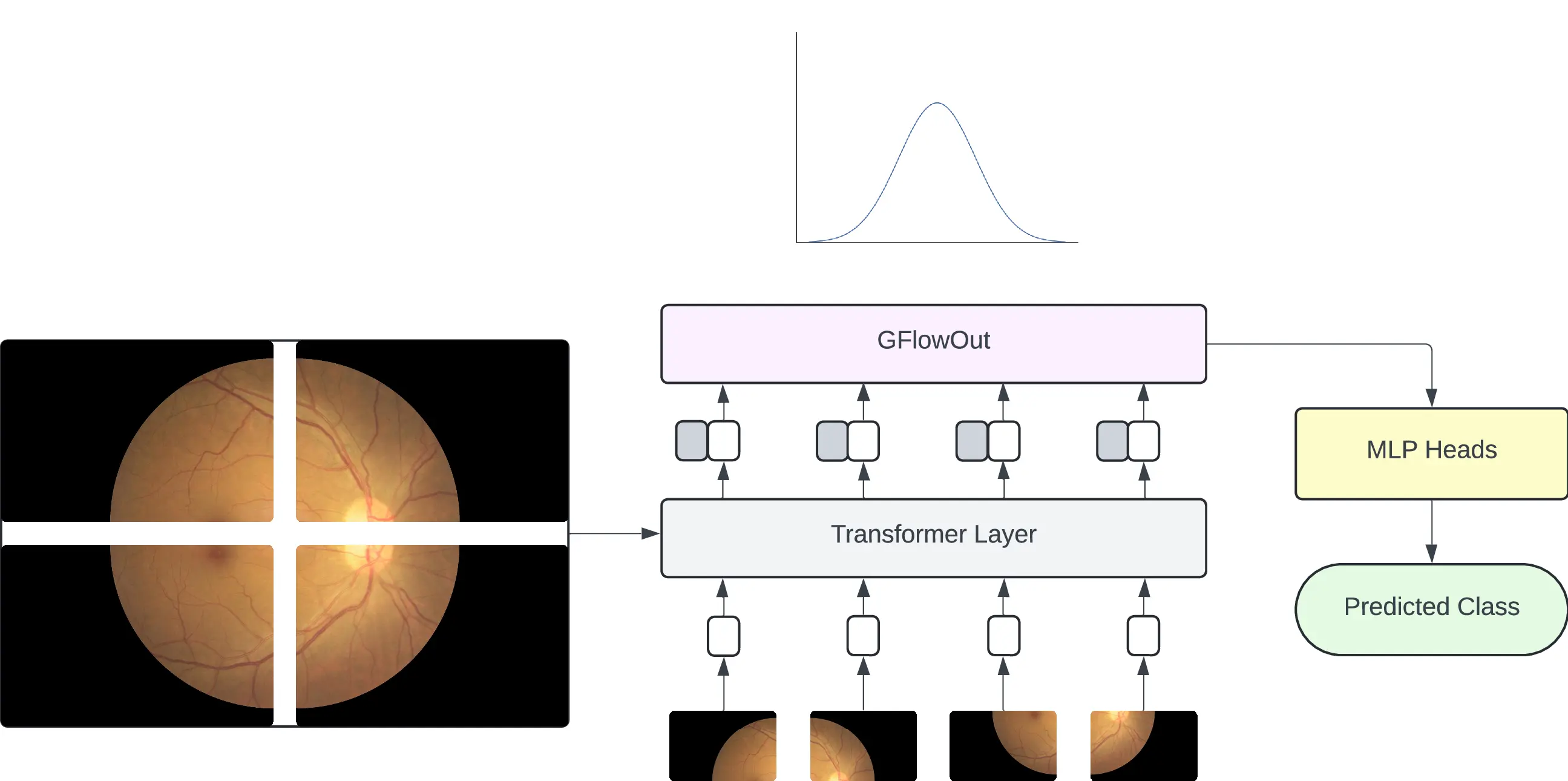
Method
In our approach, we integrate learnable probabilistic discrete latent variables into established vision models by implementing GFlowOut within the architectures of ResNet18 and Vision Transformer, which serve as the backbone models. To achieve this, we modify specific layers of these models to incorporate GFlowOut functionality.
In this study, we employ four types of masks: none, random,
bottomup, and topdown. The none mask indicates the absence of any
applied mask. The random mask functions similarly to traditional dropout layers, applying a
randomly generated mask, thereby mimicking the behavior of standard random dropout.
The bottomup mask generates dropout masks based on both the input data and the contextual
information from previous layers, allowing for a more data-driven computation of the dropout probability
distribution. In contrast, the topdown mask creates dropout masks solely based on the
contextual information from preceding layers, without incorporating any direct input data.
Results
Eye Disease Detection Experiment
The models were trained using NVIDIA Tesla P100 GPUs for 100 epochs. The dataset was divided into
training and testing subsets with a split ratio of 0.2, ensuring a robust evaluation framework. During
the training process, both models were subjected to all four different map types, with the results
tabulated for comparative analysis. Our findings indicate that the Vision Transformer generally
outperforms the ResNet model. However, when focusing on the same backbone model,
the bottomup mask emerges as the superior performer, delivering the
highest accuracy among the tested configurations. Conversely, the model with no mask applied exhibited
the lowest accuracy levels, underscoring the critical role of appropriate masking strategies.
We also performed experiments with noise added to the images, which revealed insightful results. Models equipped with GFlowOut showed enhanced performance compared to their standard counterparts, even under noisy conditions. Remarkably, the accuracy of these models with GFlowOut remained comparable to scenarios involving non-noisy data, underscoring the robustness of the model against different types of noise. This robustness is a significant finding, highlighting the model's potential for practical applications where data imperfections are common.
Out of Distribution Evaluation and Entropy Calculations
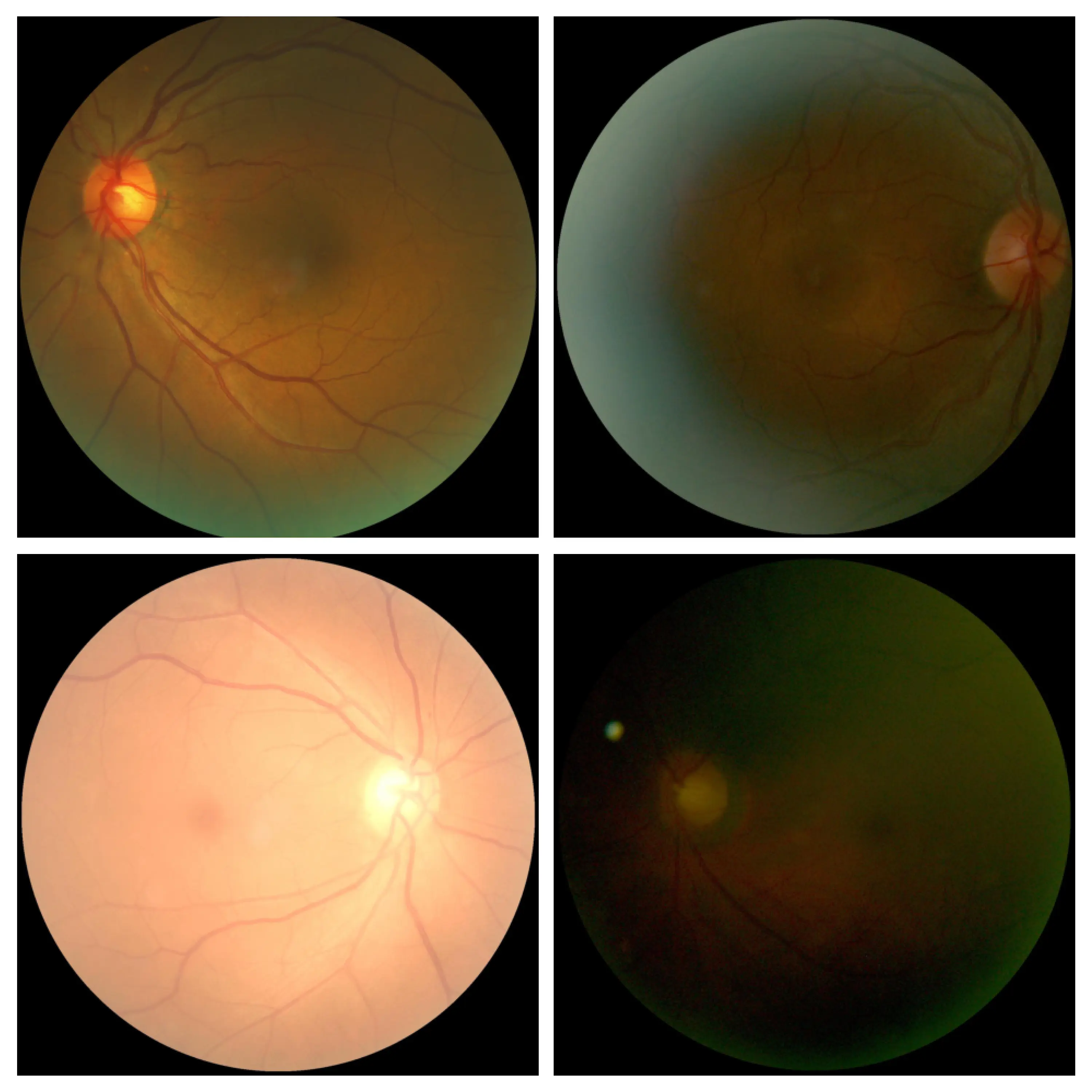
To thoroughly evaluate the performance of our model, we tested it on out-of-distribution (OOD) datasets and calculated the entropy of the forward pass results. Specifically, we utilized the JSIEC dataset (JSIEC) as our OOD dataset for evaluation. The JSIEC dataset, recognized for its comprehensive and diverse collection of eye images, presents significant challenges, making it an ideal benchmark for assessing the robustness and generalization capabilities of the model.
In our evaluation process, we performed multiple forward passes on both the training and evaluation datasets. By calculating the entropy of the outputs from these forward passes, we quantified the uncertainty in the model's predictions. Typically, higher entropy values indicate greater uncertainty, while lower entropy values suggest more confident predictions. By analyzing these entropy values, we identified patterns and differences in the model's performance on in-distribution versus out-of-distribution data. This analysis also enabled us to pinpoint specific images within the datasets associated with high or low entropy. Images with high entropy often highlight areas where the model struggles to make confident predictions, revealing potential weaknesses. Conversely, images with low entropy indicate areas where the model excels, making accurate and confident predictions.
Specifically, we conducted five forward passes using the ViT-GFN model on both the training and evaluation datasets. For each pass, we computed the minimum, maximum, and average entropy values. These results are systematically presented in Table \ref{tab:ood-experiments}. By examining high and low entropy images, we gained a deeper understanding of the types of data our model handles effectively and the types that pose challenges. This information is crucial for guiding future improvements and fine-tuning the model to enhance its overall performance.
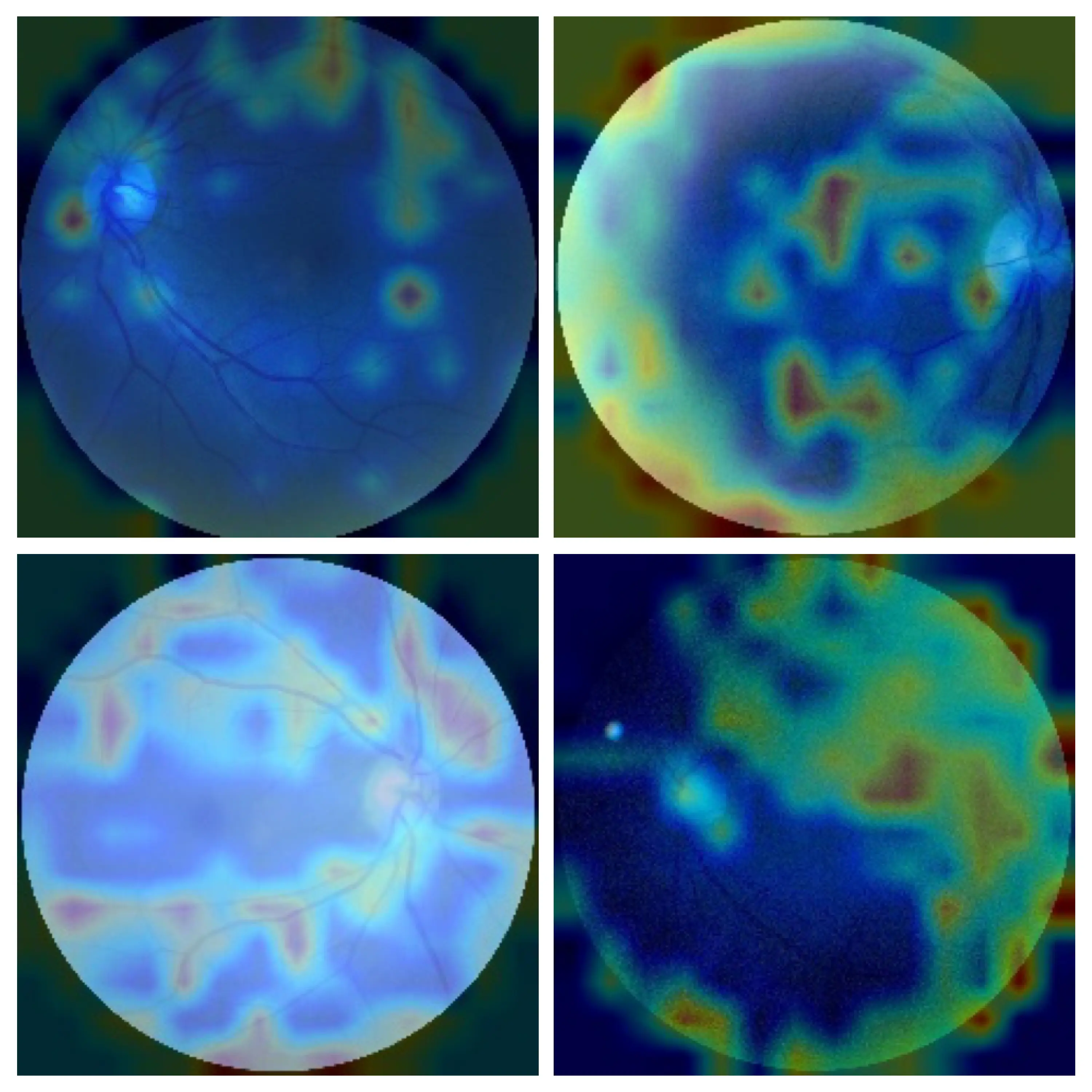
To further explore the explainability of our model, we visualized the attention maps of the Vision Transformer model. Using the PyTorch GradCAM implementation, we generated attention maps and overlaid these maps on the original sample images. This visualization highlights the regions of the image deemed important by the model, thereby enhancing our understanding of the model's decision-making process.
| Dataset | Min Entropy | Max Entropy | Avg Entropy |
|---|---|---|---|
| ODIR | 0.408967 | 0.663598 | 0.506282 |
| JSIEC | 0.470288 | 0.69244 | 0.564921 |
Conclusion
In this study, we present a novel methodology for advancing eye disease detection by integrating learnable probabilistic discrete latents via GFlowOut within ResNet18 and Vision Transformer architectures. Our approach has demonstrated substantial improvements in both accuracy and robustness, particularly under challenging conditions such as noisy data and out-of-distribution scenarios. Empirical evidence reveals that the use of bottom-up and top-down dropout masks, specifically tailored to the dataset, significantly enhances model performance, surpassing the effectiveness of conventional dropout methods. Additionally, the entropy analysis provided critical insights into the model's predictive confidence, highlighting areas for further optimization.
By enhancing the model's capacity to generalize and manage uncertainty, our approach marks a pivotal advancement in the development of reliable AI-driven diagnostic tools for clinical applications. Future research should investigate the broader applicability of this method across other medical imaging domains and focus on refining the model to improve its interpretability and clinical relevance.